Debugging Service Processes on Windows is a bit tricky – the old IFO / Debugger trick doesn’t work anymore, because services run in their own session.
Also, when you attempt to debug a service process by attaching your debugger to it, you will often come across this error message:
ERROR_SERVICE_REQUEST_TIMEOUT 1053 (0x41D) The service did not respond to the start or control request in a timely fashion.
or its GUI equivalent:
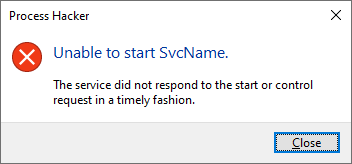
Luckily, we can adjust the value of this timeout by modifying the following Registry DWORD value:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\ServicesPipeTimeout
The ServicesPipeTimeout value represents the time in milliseconds before a service process execution times out.
We can modify this value and set it to say… 5 minutes = 300,000, and then we must restart our test system.
With that change, we buy a lot of precious time that we can now utilize to attach the debugger to the service process before it times out.
The next problem is catching the moment the service process executable actually starts.
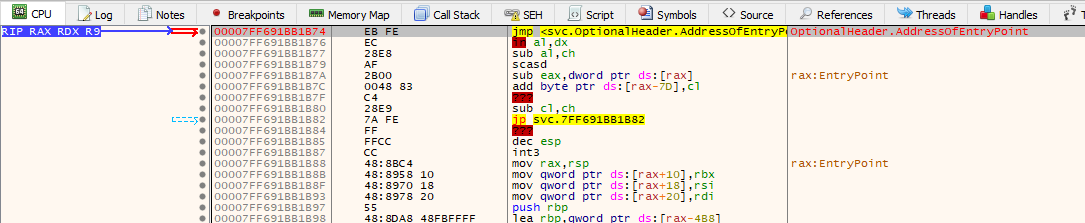
Here, the good ol’ ‘never-ending loop’ trick comes to the rescue. We take the executable that the service points to, and modify its entry point to 2 bytes: EB FE. This is an opcode for ‘jump to the beginning of the jump instruction’ aka a never-ending loop.
With that in place we are now ready to go.
The last thing to do is launching an elevated instance of your favorite user-mode debugger — this is to make sure we can attach it to a privileged service process.
Let’s go:
- Modify the ServicesPipeTimeout timeout value
- Restart the system
- Stop the target service process if it is running (helps to change it to ‘Demand Start’ as well)
- Patch the target service process binary’s entry point (or any other place where you want to break into when you attach the debugger); note: you can copy the service process’ binary to a different location and patch it, and then modify the service configuration in the Registry to point to it (HKLM\SYSTEM\CurrentControlSet\Services\<target service>\ImagePath)
- Launch the debugger, elevated
- Start the target service
- Go to the debugger and attach it to the service process
- You should now see the debugger breaking on the never-ending loop
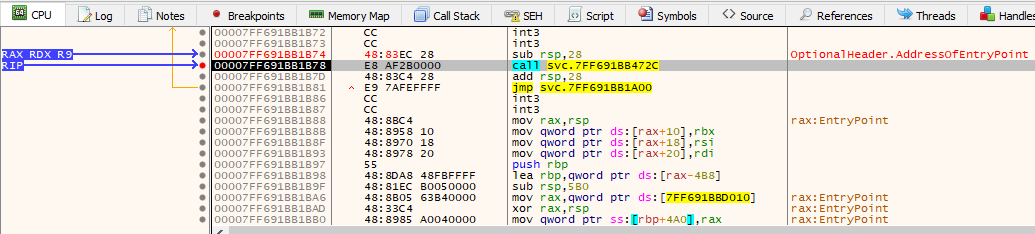
- Make a hardware execution breakpoint on the next logical instruction after the patched instruction at the entry point; this is your backup plan if the patching you do in the next point causes the program to runaway (not sure why, but it happens under xdbg)
- Patch the EB FE back to original bytes
- The program may now runaway, but your hardware breakpoint should stop the execution on the next instruction
- Start putting the breakpoints on APIs you want to break on:
- StartServiceCtrlDispatcherA
- StartServiceCtrlDispatcherW
- OpenSCManagerA
- OpenSCManagerW
- CreateServiceA
- CreateServiceW
- RegisterServiceCtrlHandlerA
- RegisterServiceCtrlHandlerW
- RegisterServiceCtrlHandlerExA
- RegisterServiceCtrlHandlerExW
- SetServiceStatus
- etc.
- Run!
- Analyze!
We can test this process using the SvcName service example from Microsoft. The only modification to their source code we need to add is this:
StringCbPrintf(szPath, MAX_PATH, TEXT("\"%s_patched\""), szUnquotedPath);
inside the Svc.cpp file.
This will ensure that our compiled Svc.exe can still work, but the installation of the service will point its binary path to Svc.exe_patched (that’s the one with the entry point we will manually patch to EB FE).
The moment we attach the debugger:
We now patch the entry point back and our hardware breakpoint stops the execution:
We can let the code run until the breakpoint on StartServiceCtrlDispatcherA:

We are now in control.
Bonus:
- It helps to run Procmon with the filter on your service process’ events on as it may speed up analysis
Things that are weird:
- Despite changing the timeout to just 5 minutes, I noticed that I could often analyze the service process for much longer than that; I don’t know the exact logic at play here
- The after-patch-code-execution-runaway is an anomaly; it could be a bug in xdbg, I don’t know
- Microsoft example service process code compiled at first go, w/o any troubleshooting 😉
- The ServicesPipeTimeout timeout value affects all services, so if you happen to have some broken service you may see delayed system startup
There are probably other, and probably better ways to analyze windows service processes out there, but… old school is cool.