Running typical ‘strings’ tools over a suspicious file provides lots of useful information.The output typically provides an immediate clue what the file’s purpose is e.g. is it a text file, binary file, what is its file format, character encoding, is it compressed, what APIs , file names and URLs it is referring to and so on and so forth. If you are lucky, you may sometimes get a visual output as well e.g. an ASCII art as it is in a case of well-known web shell r57.

Now, the problem with ‘strings’ tools is that they are usually monolingual. They extract English strings in ANSI and Unicode format, but forget about other languages. That is, they are unable to recognize strings that are non-English. Of course, it is non-trivial to write a tool that will recognize strings in a few dozens of languages, as they all use various types of character encodings and each character can occupy not only a single byte, but in many cases multiple bytes.
RUStrings.pl is a simple perl script that tries to address this issue and while it focuses only on Russian strings, it can be relatively easily extended to cover other languages. The strings it extracts include
- ANSI
- Unicode
- 4 different Russian character encodings
The output will contain Cyrillic characters and has to be viewed with a proper program supporting various character encodings.
Compare the following:
- obtained via ‘strings’:

and
- via ‘RUStrings’:
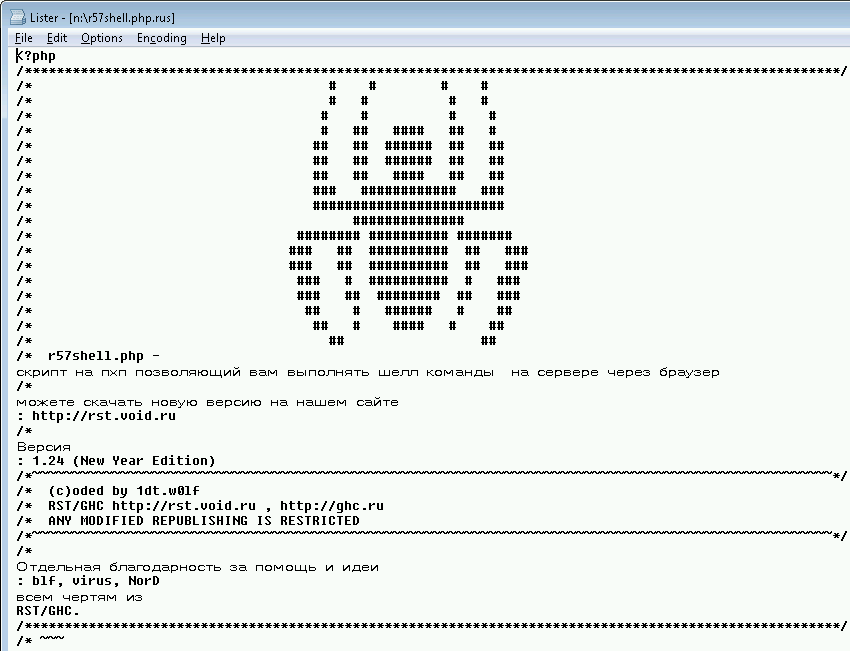
In case you are wondering what tool I am using to preview these – it is Total Commander’s built-in Lister viewer – it has a very cool feature that allows changing the character encoding on the spot making Cyryllic (and others) characters ‘visible’.

Download