In my last post I mentioned the outdated PAD files. Let’s have a closer look at them.
Before we do so, a short comment first — in the era of omnipresent GenAI buzz sometimes it’s really hard to convince yourself to do any research let alone share the results of it. Everything feels ‘old’, the GenAI obviously knows all the answers, and no one can compete with this vast amount of information that can be extracted from these AI models so effortlessly, even if their advice sometimes feels a bit hallucinogenic…
What keeps me going is the good ol’ adage – luck favors a prepared mind. I believe that you can’t utilize GenAI properly if you don’t know the fundamentals, if you don’t do the legwork, if you don’t research on your own. Ironically, in order to use GenAI efficiently and effectively one has to know far more than before because GenAI is a very strong, confident assistant that often… turns an opponent. It may assist us in the best possible meaning of the word, or can ruin us, if we blindly trust its outputs…
The surprising twist is that we can only get better at using the GenAI by first getting better at the ‘non-AI’ stuff aka ‘the old’. And this post is dedicated to ‘the old’.
Yes, no one cares about PAD files anymore, so why bringing them up? Well, I hope I will convince you that there is still value out there…
So, the PAD files…
It’s hard to download them today, but in the past one could download PAD files from at least these 2, now defunct websites:
http://repository.appvisor.com – repo of actual PAD files
http://www.qarchive.org/repository – XML file with links to PAD files
Luckily, old copies of QArchive repository still reside on https://web.archive.org f.ex. here (28K+ PAD URLs), and I will share 14K+ PAD files from http://repository.appvisor.com below.
When you attempt to download all the PAD files possible, and/or the URLs they point to, you will quickly realize that many links no longer work. Not a surprise, after all, it is a legacy protocol, and lots of killer-app-wannabe software products never really made it, and in the end – their presence online was barely noticeable. For the purpose of our discussion though, it’s worth mentioning that one can still use webarchive.org to download the copies of these PAD files from the time right before the website hosting them closed… so yes, there is a way to collect many of them, even if they are officially long gone.
Analyzing many PAD files (in bulk) can give us an insight into many interesting aspects of a shrinking, yet still present old-school software distribution model.
For starters, analysing a repo of many PAD files gives us a quick&dirty software categorization list: whatever is listed inside the Program_Category_Class element is of interest. An example category list extracted from 14K PAD files is shown here. By mapping Program_Category_Class to directories that programs are installed to (can be extracted via installer unpackers), one can build a simple categorization engine for these known combos.
The Primary_Download_URL, Secondary_Download_URL, Additional_Download_URL_1, Additional_Download_URL_2, DP_Distributive_Primary_URL elements point to actual URLs that you can use to download the latest version of the software. One way to utilize these is to collect a list of (most likely) clean software installers that can be used to build your ‘good samples’ repo. This in turn can be used to tune and quality-test your yara, yara-x, capa rules…
The Company_Info element and its children may help to collect useful info about (most likely) legitimate companies – there are emails, phone numbers, social media accounts, etc.
Believe it or not, many of these software products still exist out there, in the wild. They are installed on actual endpoints and the information provided inside these PAD files can help us to do 2 things:
Recognize them as ‘possibly legit, good software’ –> exclude from the detections/forensic exam view!
Recognize and categorize them to build a profile of the endpoint and the org (as discussed in my previous post).
Last, but not least – this is an archive of 14K+ PAD files from http://repository.appvisor.com I downloaded in 2021.
Now… for the bad news.
Analysis of PAD files will give you a list of no-longer-existing domains that may be vetted as trusted by security vendors due to past encounters when the software was still alive. Secondly, some of the existing, installed software packages that happen to be ‘dead’ by now may still include auto-update functionality. Yes, this offers a supply-chain-attack possibility where one can re-register an expired domain and place the malicious updater on this new site. Next time the legitimate autoupdate of now defunct software kicks in, it will now resolve the domain, download the updater and execute it.
(this is a very long post, sorry; took weeks to distill it into something that I hope is readable)
As promised, today I am finally going to demonstrate that the piracy is good! (sometimes)
In order to do so, I need to start in a non-sequitur way though…
There are two questions that today’s forensic and telemetry technologies fail to answer quickly, let alone clearly:
What will I find on this SPECIFIC system/endpoint?
What will I find inside this ORG? (2a probably touches on the cloud as it’s gaining momentum in this era of a digital transformation)
The first question is super important.
Before we even start that basic forensic triage, kick off these evidence collecting scripts and heat up the pipelines focused on automated forensic data processing… it would be really cool to read a basic summary of what that endpoint IS all about – showing us the ‘easy’ findings first:
this system is this and that OS,
it is this and that OS version,
it is a domain controller/server/workstation/laptop,
with this and that list of updates, patches,
belongs to this and that domain…
with this and that list of running processes and services…
Nuh, just kidding… it’s a trap.
So many automated-data-extraction approaches focus on all this unimportant, but easy to extract stuff that it almost always ends up delivering something that I vehemently hate: fluff.
Let’s remember that activity is not a productivity.
That is, even with all these fancy auto-generated summaries available, the question posed above will still remain unanswered…
Why?
Because the true, honest answer to this question can take many forms, and none of them really care about the ‘easy to code, but fail to answer the basic question’ type of automation cases… What it means is that we don’t want yet another ‘quantity over quality’ vulnerability scanner’s endpoint equivalent in the house… doing forensic-wannabe job, but in the end delivering nothing, but non-actionable, confusion-soaked nothingburgers.
So, without a further ado, let’s demonstrate how a proper answer could look like (and it’s 100% hypothetical). I hope you will agree that any subset of the below could be helpful:
There are two active users on this system: FOO and BAR (active=used the OS recently aka within last few days/week/month – should be precisely defined)
The user FOO appears to be a gamer, because we see the following games installed on the system and they are being executed repeatedly when that FOO user is logged in: C:\gamea, C:\gameb, C:\gamec, …
The user FOO keeps all the personal files in the following directory: C:\XYZ – this is based on metadata extracted from all documents stored inside this folder
The second user of this system (BAR) appears to be an accountant – there is a stash of accounting files stored in the following directory: c:\beancounters; this user doesn’t seem to be playing any of the installed games; still, it is questionable that the user BAR stores possibly sensitive customer accounting data on the system on which the user FOO is playing games…
There is a stash of sensitive files stored in the following directories: c:\secret, d:\confidential; we don’t know who created these folders, but a couple of PDFs inside the c:\secret directory seem to be password-protected, and a few files from d:\confidential directory reference strings ‘TOP SECRET’ and ‘TLP;RED;’ – they may be of interest
There is a number of manually created folders that may be of interest: c:\beancounters\new folder, c:\beancounters\nouveau dossier
Whoever created c:\beancounters\nouveau dossier may be a francophone
A number of dashcam videos appear to be stored inside the following folder: c:\dashcam; they cover the dates between 2024-01-01 and 2024-02-05
There is a plain-text file that appears to be storing secrets: c:\aws\creds.txt
There is a pr0n collection stored inside the c:\updates folder
The Instant Messengers apps found on this system are: Skype, Telegram, WhatsApp
Portable Tor seems to be installed in c:\Tor directory
There are 2 email clients recognized on the system: Outlook, Thunderbird
There are 3 Instant Messaging programs recognized on the system: Telegram, Skype, Signal
Do you see what I am talking about here?
The art of quick, meaningful but also early system profiling based on the existing forensic evidence!
And yeah, it’s not an easy task, it’s also not fool-proof, and yeah, we can’t just rely solely on regular expressions or AI here that can be applied to various forensic artifacts discovered during triage/preliminary analysis, but… anything goes… any decent commentary we can provide about the actual system’s content before any manual forensic exam starts… is a decent start! Does it bring a bias to the exam? 100%. Does it make it easier to automate triage towards this bias? 100%.
What I posit is this:
Given the advances in forensic technologies related to data acquisition, data collection, data processing, data triage and data analysis automation (plus maybe AI), are we in a position to move the evidence analysis flagpole forward towards… maybe not the ‘one click solution’ yet… but kinda towards it, anyway? Saving lots of personhours in the process?
And if we extrapolate…
The question #2 is very fascinating as well…
What will I find inside this org?
Your asset inventory, your SBOM, your ad hoc queries combing through recent process/file/service creation telemetry are all adding value… BUT… it’s not working, long-term.
Why?
Collating information from various (very dynamic in nature) sources is HARD. The IT sector is still firmly stuck in a Don Quixotic notion believing that we can create a perfect asset inventory using available people, process, technology adjustments, but the reality is far more complicated than that and even more nuanced…
First of all, even today it’s most of the time done in Excel or Google Sheets. Yup! and Yuck!
Secondly, since it is usually done manually, it often expires before it even gets to the production level; hence it’s always marked as a ‘work in progress’.
Thirdly, it’s usually owned by, and then created and maintained by people with a mindset of a single shop owner that likes to count beans, and not driven by that very wild, and far-reaching concept of co-ownership… where n-dimensional, distributed, tech debt and post-many-M&As -heavy digital transformation riders follow well-defined processes that make the asset inventory ‘build and maintain itself’. Getting there requires a lot of thinking, trial and error though, and many transformations later, many processes creations and/or adjustments later we may eventually win. Otherwise we always end up working with the old data. I don’t know if there is any company out there today that is doing it 100% right, so yeah… here’s your new startup idea… 🙂
On a practical level…
The first step to a workable solution for an asset inventory is a solid understanding of a snapshot concept,
The second is a proper understanding of that snapshot’s scope – it is a constantly moving part,
The third is the concept of data accumulation, tagging, and expiration – you don’t want garbage in -> garbage out situation,
The fourth is leveraging as many security controls as possible – they are the most accurate sources of information as it’s literally endpoints and/or devices reporting something – meaning: they are live in your environment!,
The fifth step is automation – script it, macro it, whatever… let it do/refresh itself,
The sixth is that all the points above are a subject to a multiplier – regulated markets, customer demands, tight contractual obligations will take your asset inventory into many uncharted waters
The bottom line is: there is no such a thing as an asset inventory. There is an asset inventory process. It’s a living thing, very dynamic and capricious in nature and it’s time to start treating it as such. Does it sound familiar? Yes… Security is a process, not a product/tool, too.
We can’t win all battles, but we can settle on winning the important ones.
If we think of it… the new assets don’t appear out of nowhere – new employees join, cloud systems are being created via API or UI, data center computers (both physical and virtual) are being added, acquired, leased, deployed, new IoT devices are being added to the network because a reason, and new devices are being added to the production, let it be corp, dev, lab, guest networks any time of the day, and so on and so forth.
The very same can be said about asset decommissioning – laptop’s battery got swollen and laptop is out, laptop got old and is out, company laptop uplifting/upgrade program replaces the old devices, and then sometimes a random laptop is lost or stolen, and then it’s out, and then that specific cloud system that was active for 1 month only and then terminated by a script, is out, or an employee was fired and the employee’s laptop got wiped out and got back to the available pool of laptops, and so on and so forth. It’s all very complicated when you look at it as a whole, but it becomes far easier when we realize that every single case involves SOMEONE or a SCRIPT doing SOMETHING that affects the state of the asset inventory snapshot.
If any sort of a process to handle these use cases is actually defined, described, and present at any given time… everything else falls in place. Including the contribution to maintaining the best asset inventory ever. Sorry, I meant… following the asset inventory process, that is.
If we dig deeper, we should start looking at our application inventory too — you know, the asset inventory bit covering all the software being used at the company. The naive approach focuses on:
enumerating the Registry and (rarely) localized and/or architecture-specific versions of c:\program Files directory for Windows,
enumerating /Applications folder and/or ‘kMDItemKind=Application’ and/or ‘kMDItemContentType == ‘com.apple.application-bundle’ items for macOS/osx, and
some amusingly undefined processes for analyzing Linux OSes to discover all installed software that covers various versions of packagers (dpkg, rpm, apt, etc.).
Of course, we miss the whole class of software that is marketed as ‘portable’ and can be installed and stored in some random directories on the system. Of course we miss the whole class of software that are browser plugins, email client plug-ins, and <any type of program> plug-ins. Of course we miss the whole class of cloud/web-based software. Of course we miss the whole class of software code that is hidden inside some random nim, pip, go packages. Of course, we miss a lot of software that is directly incorporated or embedded from many resources outside of our control…
And there is more…
Have you ever heard of Homebrew, Chocolatey? Then there are legitimate App stores, dodgy App stores, warez sites, hacktools, ppl learning pentesting on the job and playing with hacking tools downloaded into, and executed from random places, random software repos introduced by downloading and unpacking random archives, and… of course… the internal software developed at the company — lab, and dev environments are code rich and include lots of test, ad hoc compiled code that is often not very useful and add nothing to the whole idea of asset inventory, but may trigger AV/EDR alerts.
Still, the idea of asset inventory snapshot comes with a territory. Be invasive, be scrupulous. If any of them uses external, often unpatched libraries that may be vulnerable (f.ex. log4j, libcurl), we certainly want to ‘see’ them, too.
There are so many unknown unknowns out there that it is scary. And it should be.
This is why we can introduce a number of enhancements to our asset inventory process concept:
We can continue to build an all-inclusive physical and virtual asset inventory for devices by defining solid, fool-proof processes for onboarding and decommissioning these assets
Same as above, we can continue with software-related asset inventory BUT
We can also manage/limit installation of unknown software (allow-listing, signed-only, support-vetted, etc. OR free-install in DIRTY network segments),
We can also automatically create snapshots of software-related asset inventory that is either KNOWN or UNKNOWN,
We can attempt to CLASSIFY software-related asset inventory based on RULES
We can and should strive to better identify NEW assets of either hardware or software kind using available telemetry, both EDR and XDR-based
Enter the art of artifact collection and hoarding for the sake of forensic exclusivity.
Knowing as many known programs as possible is helpful.
Knowing means:
intimately knowing the installer file names, as well as list of file and registry changes introduced by the software installer and its many versions,
same goes for IPs/DNS entries,
same goes for mutex, atom and semaphore names,
knowing version info details of all binary components (EXE, DLL, SYS),
knowing signing details for all binary components (EXE, DLL, SYS),
knowing what sensitive files the software produces (config files, encrypted configuration/credentials files, etc.),
knowing the category the software belongs to (instant messenger, email client, graphics program, etc.),
etc.
The second last bullet point is where I am finally going to demonstrate that the piracy is good! (sometimes).
You may collect lots of software packages for analysis, you may excel in installer unpacking and analyzing, but I think nothing will beat the software categorization that pirate sites offer. There is a lot of crowdsourced information available on warez sites that we can think of leveraging/utilizing. Whether it is a torrent site, magnet link site, and/or a good-old (S)FTP or Usenet site, or even one of many prevalent open directory type of resources, they almost always come with some sort of categorization in place…
We can web scrap and web spider these sites, we can build classifiers based on folder and file names, archive names, internal file names, directories and registry keys present in all these creations (some present inside the installers).
Luckily, there is more.
The bitter truth is that anyone trying to classify 20-30K software packages ‘present’ or ‘discoverable’ inside your average org is going to have a hard time.
The ‘warez’ angle is useful, but it’s probably the least impressive/important. So… piracy may be useful, but not adding much value.
Why?
The more advanced and detailed software classification approach is already available on the internet. All over the place. You go to your random/favorite software downloading site and you can see all these software packages arranged and categorized. You can web scrap/spider it too.
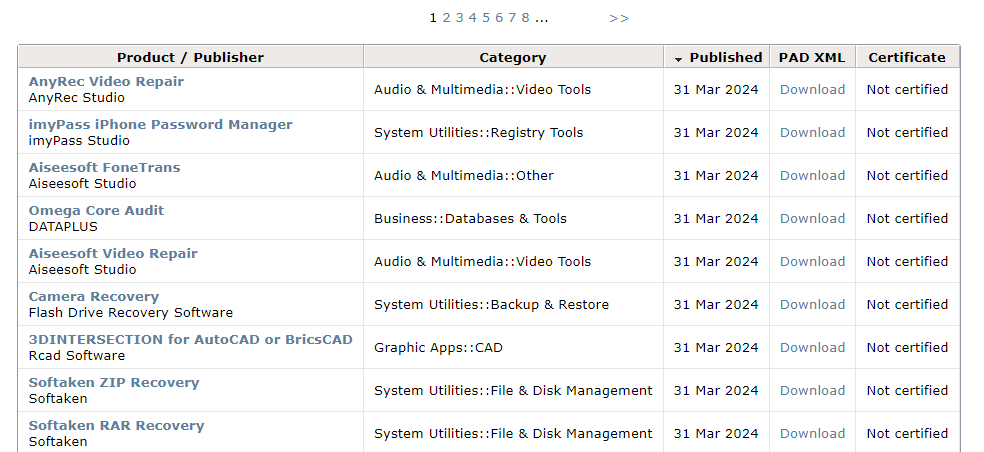
Then there is the whole business of PAD files. It’s an old, XML-based, software description standard developed by the Association of Software Professionals. The more PAD files you can download and parse, the easier it may become to classify software found in your org! Of course, the ASP ceased to function in 2021. The very useful http://repository.appvisor.com/ page is no longer in operation, but we can still find its snapshots on Web Archive – last saved on March 2024. The categorization bit available there is gold and should be preserved!:
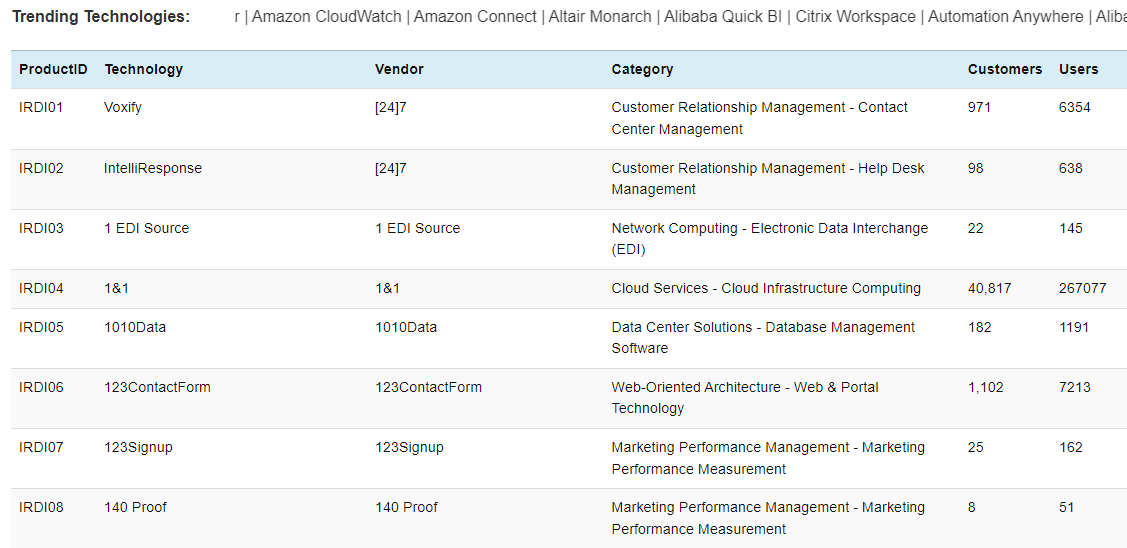
Then there is a completely new level of abstraction: SEO-driven web pages. There is a lot of websites that list a lot of references to categorized software packages f.ex TechStack:
These are great points of reference and we should utilize them as well.
And there are also websites that very much still live in the past: oldversion.com, majorgeeks.com, etc. After exploring these resources for a bit, you may realize that a lot of software available today and that can be found on org endpoints is not only already very well classified, but it is also hard to miss…
When you explore a couple of ideas presented here, and data available on a couple of other sites you suddenly realize that we live in a very well-established software ecosystem – there is (actually) a very limited number of GOOD software packages for each type of software.
Now, I must be honest. The usefulness of all this is questionable today. The digital transformation has changed the way we use computers. The desktop computers and workstations and even dedicated servers are becoming obsolete and outside of some specialized tasks (gaming, research, hosting, etc.), the modern portable devices are nothing but thin clients we use to access the ‘always-most-up-to-date’ version of web-hosted software…
In a way, this article is an example of cyber Elephants’ graveyard. If you still need to do old-school endpoint/device forensics, it may inspire you. If you don’t, you will perhaps scratch your head and move on – this is a different type of ‘forensic exclusivity’, of course, but it’s a good one. Because everything we will ever witness in this game is a subject to an ever-changing process. One that is always outside of our control.