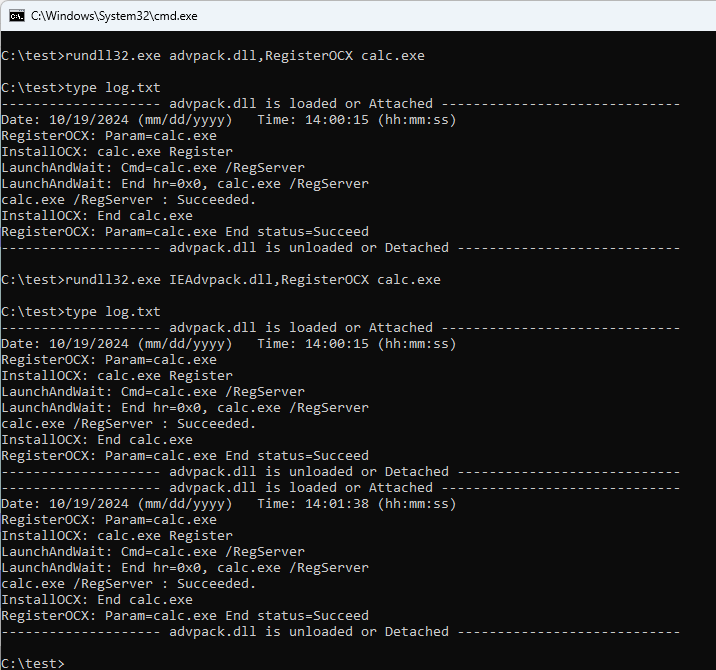
There is a very old hack out there that enables logging for the advpack.dll and IEAdvpack.dll DLLs. Many of their functions include the logging, so enabling this may help to pick up some old-school forensic logs. Of course, the value of it today is superlow, but it’s an interesting feature nevertheless, and in a way similar to WinHTTP logging I covered in the past.
To enable this feature we simply add this Registry entry:
I don’t even know how to start. I wrote about old InstallShield setup before, and today’s topic is very similar – the old, yet still present setup file residing (on Win10, 11) in the following location:
c:\windows\SysWOW64\setup16.exe
Running it gives us this misleading message box #1:
After quick study of setup16.exe code I was able to determine what command line arguments it needed and then craft a simple example LST config to act as my setup file.
The program accepts the switch -m that allows us to pass a name of an alternative LST file to it, so we can run a command like this:
Creating a dummy file c:\test\test.lst and running the test we get this misleading message box #2:
After analyzing the code a bit more and then looking at some very old examples of LST files that can be found online I was able to quickly create a test file that worked…
Additionally, I discovered that we can use -QT argument to run the program in a QUIET mode (no dialog box, no error messages).
This is not a proper config per se, because it just provides a number of mandatory fields that are filled-in with dummy values, and it does not have the ‘Files’ section that is kinda mandatory, because it lists ‘installable’ files. The reason it still works is, because it leverages a ‘background’ feature that forces the setup16.exe program to relaunch a new setup program using a command specified in a ‘background’ field, and in this case, our new setup is just a Windows Calculator.
There is obviously more ways to launch programs via the LST file f.ex. by using the snippet similar to the one shown below. This time we rely on a ‘proper’ program execution field which is ‘CmdLine’. It is important to mention that the value of this field is interpreted as a relative path to the path of the working directory of the installer, so I added a few ‘..\’ to traverse the path back to the root of the drive, so we can then use a full path to reference Windows Calculator we launch for testing purposes.
The animation of two scenarios in action is shown below:
It’s worth covering a few more quirks of this program.
One is the silly way it appends the ‘LST’ to the file names passed to the program via the -m command line argument.
When we invoke the program like this:
c:\windows\SysWOW64\setup16.exe -m c:\test\foo
we will get a very confusing message #3:
For a similar invocation:
c:\windows\SysWOW64\setup16.exe -m c:\test\foo.
we get a less confusing message #4:
And another one:
c:\windows\SysWOW64\setup16.exe -m foo
It would seem parsing of the command line arguments and interpreting them is not this program’s forte (there are obviously assumptions being made about how the file name passed to the -m command line argument must look like for ‘this to work well’).
Also, skipping the -QT argument leads to this windows being created (plus a message box signalling an error appearing soon after):
Last, but not least — you need admin right to run this show: