Most of the stuff I publish here are stories of a successful research. Today, for a change, I will talk about a little failed project. Little, because I didn’t spend too much time on it, failed – because it did fail 🙂
I think it is important to talk about such projects as well, because not only we do fail many times in our research activities + who knows, maybe someone will come up with a better, more clever idea than me and make it actually successful.
In the Beyond good ol’ Run key, Part 22 series. I talked about perl2exe and how the executables created using this tool can load some other arbitrary perl scripts. So, when I found out about it I thought how cool would it be to access the hidden script in a programmatic way and just dump it (assuming that I could use the fact I can load an arbitrary code as a backdoor & that I can somehow find ways to access the source code of the perl script).
Of course, if you ever dumped the hidden script from perl2exe you may wonder why would I even bother to try – knowing that the script can be easily dumped using typical reversing tricks. Well, it was simply an appealing idea to me to be able to do it in a neat way. In the end I couldn’t find a way to do it. The only consolation is that I was able to at least print the names of the routines used in the code, and enable various debugging messages.
In the aforementioned post I mentioned you can load an arbitrary perl code when the perl2exe-compiled script is loaded.
For example, we can create a (null)\sitecustomize.pl script that will be executed before the main script.
If it contains the code
print "foobar\n";
it will load like this (running the old wmi.exe perl2exed script here)
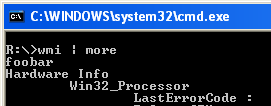
Running the code before the script is one thing, it may be handy to run code at the end of the execution as well – at that stage we will be able to enumerate some properties that are not available until the main script actually executes.
We can add the END section to our backdoor:
print "foobar - start\n";
sub END
{
print "foobar - end\n";
}
that will do the following:
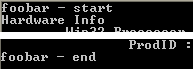
To dump the code of the perl script one needs to employ the B::Deparse module.
One can write something like this:
use B::Deparse; my $deparser = B::Deparse->new;
print $deparser->coderef2text(\&foobar);
sub foobar
{
print "Hello world\n";
}
and when executed it will print the source code of the foobar function :
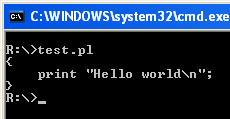
A more complex script:
use warnings;
use B::Deparse;
printit (\%main::, 0);
sub printit
{
my $hash1 = shift;my %hash=%{$hash1};
my $n = shift;
foreach my $k ( keys %hash )
{
#print "-" x $n;
if (defined $h{$k})
{
print "(hash)";
printit (%{$h{$k}}, $n+1);
}
if (defined &{$k})
{
my $deparser = B::Deparse->new;
print "$k\n";
print $deparser->coderef2text(\&{$k});
}
}
}
sub foobar
{
print "Hello world\n";
}
will produce something like this:
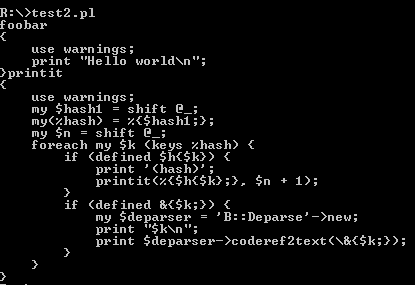
It is kinda getting close to a quine and what we need, but…
But unfortunately, B::Deparse is not available inside the compile perl2exe-compiled binary. It also doesn’t seem to be possible to include this module from a separate perl repository. One can change the content of the INC environment variable (responsible for inclusion of modules) with a push f.ex.:
push (@INC, "C:/Perl/site/lib"); push (@INC,"C:/Perl/lib" );
at the top of our backdoor, but for some reason the B::Deparse doesn’t load (the engine finds the files, but you can’t use its functionality . Perhaps the appropriate version of perl (same as in perl2exe used to compile the script) may work – this is one of the potential paths that I have not explored. Perhaps other ways to load a library may work as well.
At this stage I kinda gave up, but still played a bit with some environmental variables.
For example, adding these to the top of the backdoor (so they are executed before the main script executes):
$ENV{PERL_DL_DEBUG}=1;
$ENV{DEBUG_TIE_REGISTRY}=1;
will enable a lot of debugging messages.
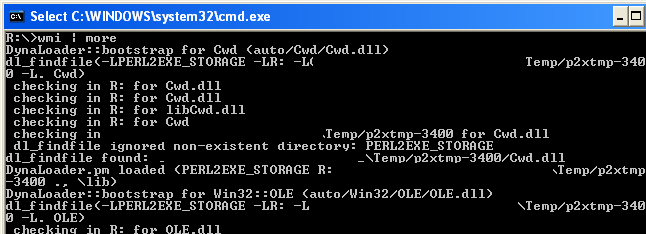
and also related to Registry:
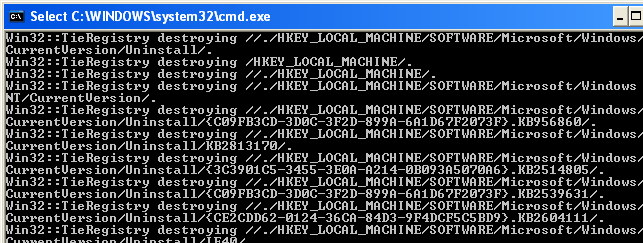
Finally, adding this bit to the END section:
foreach my $k ( keys %main:: )
{
print "FUNCTION: $k\n" if (defined &{$k});
}
so that the final script looks like
print "foobar - start\n";
#$ENV{PERL_DL_DEBUG}=1;
#$ENV{DEBUG_TIE_REGISTRY}=1;
sub END
{
print "foobar - end\n";
foreach my $k ( keys %main:: )
{
print "FUNCTION: $k\n" if (defined &{$k});
}
}
will allow us to print all the routines defined in the main script:
![]()
GetSoftwareInfo & GetHardwareInfo are indeed functions defined inside the wmi.exe – these may be still handy pieces of information if you want to quickly narrow down where the source of the original script is in memory (if you do a memory dump).
At this stage it is not a very useful piece of research. One could potentially employ this in sandboxing to produce a very detailed log, but dumping the actual source code would be a much better choice.
Was it a wasted time? Hmm probably.
If you know, or come up with an idea how to print more useful info, or maybe even a source code – please let me know.